Multora dintre noi ne este cunoscut faptul ca termenii sitemap si robots.txt sunt utilizati in asociere cu o anumita platforma sau cu un site web. In mod surprinzator, nu foarte multi proprietari de afaceri stiu despre sitemap.xml si robots.txt.
Datorita complexitatii sale de intelegere a utilizarilor, poate fi primul motiv pentru care comerciantii si proprietarii de afaceri ar putea sa nu-l considere drept o afacere profitabila. Aceste segmente pot avea o influenta semnificativa asupra structurii afacerii si a relatiei in detrimentul angajamentului clientilor.
In aceasta recenzie, vom aprofunda aspectele diferentelor majore si ale importantei Robot.txt si Sitemap.xml. Inainte de a ne incepe, trebuie mai intai sa discutam cateva puncte care va vor ajuta sa intelegeti structurile acestor segmente.
Procesul de crawling (spidering) al unui site web este diferit de procesul de indexare!
Asadar, multi dintre noi am mai auzit de termenul “crawling” in domeniul calculatoarelor, nu? Ei bine, a nu se confunda cu Indexarea unui site web. Sa elaboram:
Crawling
Imputernicit si condus de un proces software, „crawling-ul” reprezinta procesul de colectare a paginilor web printr-un software desemnat. Partea de citire este implementată pentru a va asigura ca materialele de continut asociate cu toate paginile dvs. de destinatie online nu sunt copiate.
Mai mult, urmareste mii si mii de link-uri asociate in retea pana cand se desface intr-un numar imens de conexiuni si site-uri. Acest proces de crawling este cunoscut sub numele de spidering.
Ulterior unui site de destinatie, inainte ca motoarele de cautare sa trimita roboti cunoscuti ca si spideri/crawlers pentru a gasi content nou sau updatat, robotul de cautare va cauta un document robots.txt. Daca descopera unul, crawlerul va examina cu atentie acea inregistrare inainte de a parcurge pagina.
Intrucat inregistrarea robots.txt contine date despre modul in care ar trebui să fie administrat indexul web, datele descoperite acolo vor antrena in continuare activitatea crawlerului pe acest site web specific.
Cu sansa ca inregistrarea robots.txt sa nu contina comenzi care sa interzică actiunea unui operator client (sau în cazul în care site-ul nu are un document robots.txt), va continua sa retraga alte date de pe site.
Indexarea
Imputernicita si condusa de un proces software, indexarea reprezinta procesul de indexare a continutului unui site web si apoi plasarea intr-un sistem algoritmico-depozitar (prin sistemul cloud al motorului de căutare), astfel incat acesta sa poata fi cu usurinta filtrat si gasit de cautatorii online prin intermediul unor platforme precum Google, Yahoo si Bing.
Harti ale site-ului si roboti
S-ar parea ca, odata cu trecerea timpului, complexitatea tehnologiilor poate fi uneori inevitabila, iar alteori inteligibila cu usurinta.
Cu toate acestea, intelegerea verticalelor modului in care aceste tehnologii joaca un rol asupra site-ului dvs. va poate ajuta nu doar in ceea ce priveste pastrarea si consolidarea unui anumit brand, dar creeaza, de asemenea, un canal vital pentru ca site-ul dvs. sa fie afisat potentialilor cumparatori care poate ca nu sunt in cautarea unor servicii, solutii sau produse pe care compania dvs. le poate furniza.
Ce este un Sitemap?
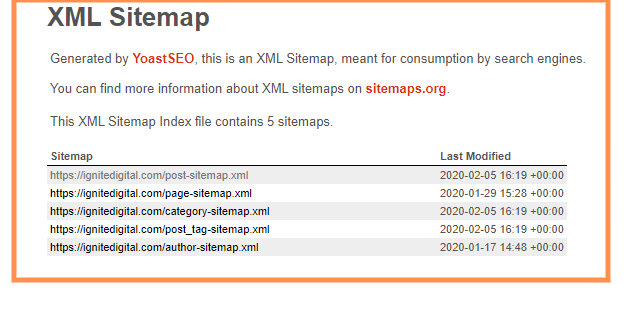
Concret vorbind, hartile site-ului (sitemapurile) sunt concepute pentru a permite Google si altor motoare de cautare importante sa acceseze in mod exceptional site-ul dvs. cu roboti de cautare. Scopul acestui lucru este de a oferi robotilor de cautare continutul unui astfel de site al companiei.
Sitemap-urile sunt configurate in doua categorii;
- A) XML – care este utilizata pentru motoarele de cautare importante;
- B) HTML – care este utilizata pentru public / utilizatori / căutători.
Ce este un fisier Robots.txt?
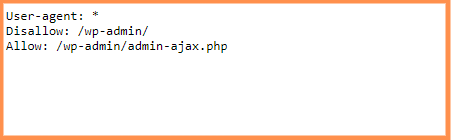
Robots.txt au sarcini bine definite. Acestia sunt in mod particular responsabili de crearea de scripturi (codate) cu instructiuni pentru a controla robotii web cu privire la modul in care accewseaza / cerceteaza pagini pentru site-uri web.
De cele mai multe ori, este implementat de dragul robotilor motoarelor de cautare.
Importanta
Trebuie sa iau in considerare acest lucru pentru afacerea mea?
Daca aveti in plan sa aprofundati lumea complexa a SEO, atunci da. Daca doriti sa obtineti o recunoastere credibila ca entitate legitima, accesarea paginilor (procesul de crawling) site-ului dvs. nu numai ca va protejeaza de intentia altor concurenti de a copia continut de pe site-ul dvs., dar va ajuta, de asemenea, sa creati o imagine legitima a afacerii dvs.
Inregistrarea robots.txt reprezinta o parte din conventia de interzicere a robotului (REP), o adunare de masuri web care gestioneaza modul in care robotii acceseaza web, acceseaza si arhiveaza substanta si servesc acea substanta clientilor.
REP incorporeaza, de asemenea, comenzi precum meta roboti, cum ar fi ghiduri la nivel de pagina, de subdirector sau de site pentru modul in care instrumentele de cautare web ar trebui sa trateze procesul de alaturare (join), (de exemplu, „follow” sau „nofollow”).
Practic vorbind, inregistrarile robots.txt arata daca anumiti specialisti clienti (programarea accesarii web) pot sau nu pot accesa so analiza portiuni ale unui site. Aceste directii de accesare sunt determinate de „interzicerea” sau „autorizarea” comportamentului anumitor (sau a tuturor) specialisti clienti.
Printre cazurile obisnuite se numara:
- Impiedicarea aparitiei, in paginile cu rezultatele motorului de cautare, a continutului plagiat (rețineti ca meta robotii sunt adesea o alegere mai buna pentru acest lucru si vom despre meta roboti intr-un capitol ulterior).
- De asemenea, sunt utilizati pe scara larga pentru a asigura setarile de confidentialitate ale unui site. De exemplu, o echipa care se ocupa cu design-ul site-ului, documentatii și alte informatii vitale, dar sensibile.
- Toate sectiunile unui site web sunt private (de exemplu, echipa care se ocupa de organizarea site-ului dvs).
- Impiedicarea afisarii paginii (paginilor) interne de cautare in orice locatii publice ale paginilor cu rezultate generate de catre motoarele de cautare.
- Verificare pentru localizarea unor astfel de sitemapuri.
- De asemenea, impiedica motoarele de cautare importante sa indexeze anumite fisiere de pe site-ul dvs., cum ar fi imagini si fisiere PDF, etc.)
- Specificarea unei intarzieri a procesului de crawling pentru a preveni supraincarcarea serverelor dvs. atunci cand robotii de cautare incarca mai multe fragmente de continut simultan este o configuratie esentiala:
- Specialist client: [numele utilizatorului operator] Nu se permite: [sirul URL care nu trebuie accesat]
In mod colectiv, aceste randuri sunt considerate documentul total robots.txt. Cu toate acestea, inregistrarea unui singur robot poate contine randuri diferite despre operatori si mandate ale clientilor (adica refuzuri, permisiuni, intarzieri ale accesarii si asa mai departe.)
Ce pot face pentru tine?
Motorul unui site de succes
Ca o regula de aur, intelegerea diferentelor majore dintre roboti si sitemapuri si modul de functionare a acestora poate ajuta intreprinderile sa defineasca in continuare radacina care functioneaza cel mai bine pentru afacere sau orice organizatie data.
Desi expunerea este esentiala pentru orice afacere, desfasurarea asocierii dintre robots.txt si sitemap-uri poate avea un impact dramatic asupra autenticitatii, credibilitatii si imaginii generale a companiei.